Mapping Bias in Journalism
February 5, 2025
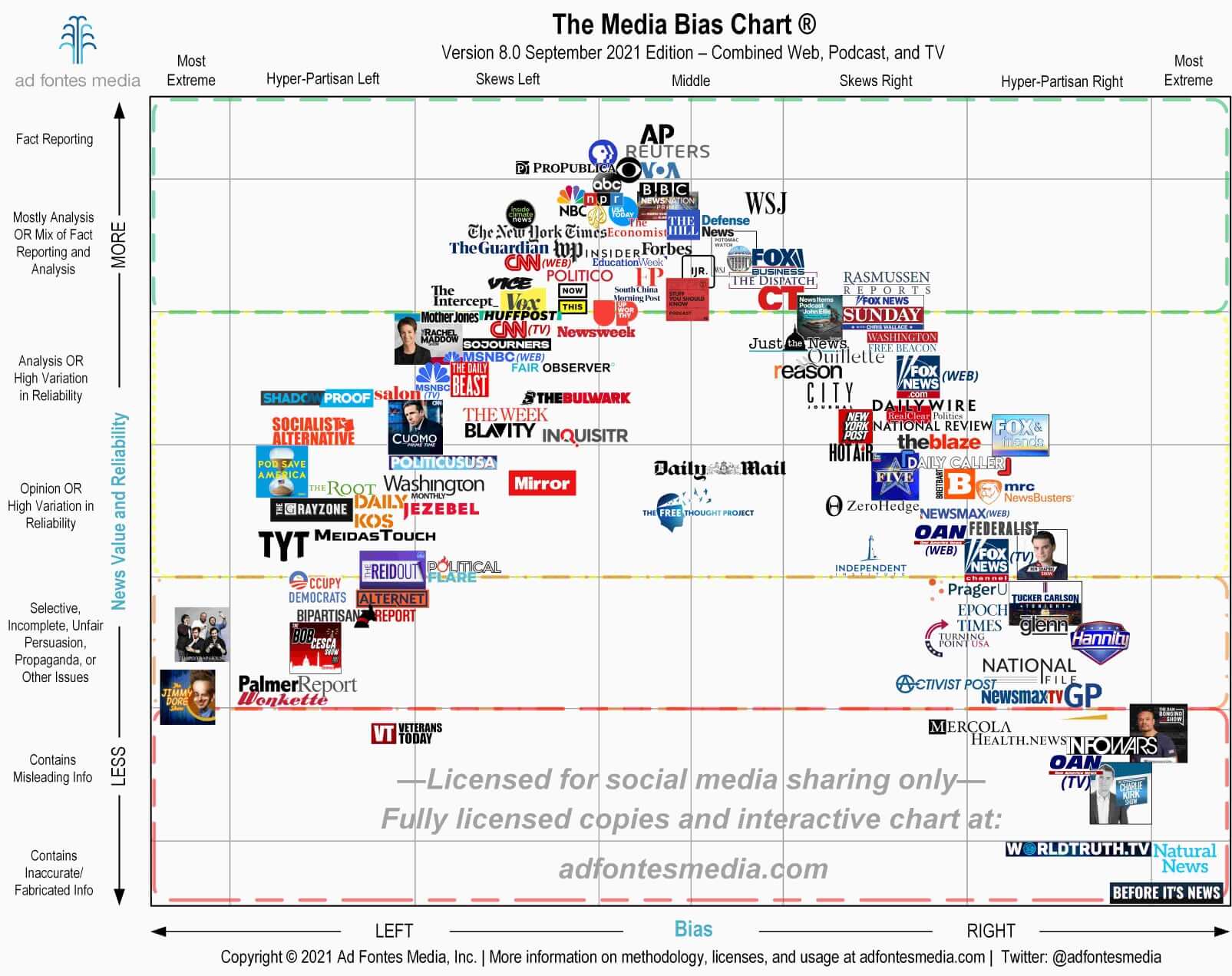
Mapping media bias has been an exploration into how information is presented, distorted, and ultimately consumed. With today's echo chambers and algorithm-driven filter bubbles, the way news is framed is often just as important as the information itself. This project is my attempt to quantify those biases, breaking down the subtle (and not-so-subtle) ways that news sources push narratives, often without the reader noticing.
The approach combines both human insight and AI-driven analysis, pulling in data from a range of news outlets through APIs and web scraping tools. From there, articles are processed using advanced natural language techniques to determine political leanings—whether that be a simple left-center-right classification or a more nuanced spectrum. The methodology is structured around frameworks like Media Bias/Fact Check and AllSides, while also integrating research on linguistic bias, source bias, and the contextual framing of news stories.
The data pipeline ensures that every transformation is consistent and reproducible. Articles are cleaned, tokenized, and normalized with tools like spaCy and NLTK, and additional feature extraction allows for sentiment analysis, named entity recognition, and keyword identification. The scale of modern media output demands automation, and the pipeline is designed to handle large volumes of data without sacrificing precision.
In the modeling phase, both traditional classifiers and transformer-based architectures are tested. An optimized neural network has already produced promising results, with a test loss (MSE) of 8.6770 and a test MAE of 1.8951. While still a work in progress, these numbers suggest real potential in quantifying bias with a high level of accuracy. Of course, AI will never replace human discernment, but it offers a level of scalability that human analysis alone can't achieve.
The data pipeline ensures that every transformation is consistent and reproducible. Articles are cleaned, tokenized, and normalized with tools like spaCy and NLTK, and additional feature extraction allows for sentiment analysis, named entity recognition, and keyword identification. The scale of modern media output demands automation, and the pipeline is designed to handle large volumes of data without sacrificing precision.
At its core, this work is about transparency. The goal isn't to label news sources as "good" or "bad," nor is it to tell people what to think. Instead, it's about creating a tool that makes media consumers more aware, more critical, and ultimately, more informed. By blending AI-driven analysis with human reasoning, this project pushes toward a more thoughtful approach to news consumption—one that prioritizes truth over rhetoric and understanding over division.